本地 RAG 智能助手 - 技术方案文档
场景 :技术方案 | 受众 :后端工程师、开发者 | 字数 :约10000字
背景与目标
业务需求
本项目是一个基于 Streamlit 的本地知识库 RAG(Retrieval-Augmented Generation)智能助手,核心业务需求如下:
| 需求编号 | 需求描述 | 来源 |
|---|---|---|
| REQ-001 | 用户可以上传多种格式文档(PDF、Excel、TXT、HTML) | app.py 文件上传功能 |
| REQ-002 | 系统自动解析文档内容并构建向量索引 | document_loader.py 、 vector_store.py |
| REQ-003 | 支持语义检索,根据用户问题匹配相关文档片段 | embedding.py 、vector_store.py |
| REQ-004 | 结合大模型生成基于知识库的精准回答 | llm.py |
| REQ-005 | 支持离线演示模式,无需配置大模型也能运行 | llm.py 的 local_echo 模式 |
| REQ-006 | 配置化管理,支持灵活调整参数 | config/app.yaml |
技术指标
| 指标类型 | 指标值 | 说明 |
|---|---|---|
| 支持文档格式 | PDF、XLSX、XLS、TXT、HTML、HTM | 通过配置扩展 |
| 文本切分大小 | 900字符(可配置) | 平衡语义完整性与检索效率 |
| 切分重叠量 | 120字符(可配置) | 减少语义断裂 |
| 向量维度 | 384维(可配置) | BGE-small 模型默认 |
| 检索召回数 | Top-5(可配置) | 控制上下文窗口大小 |
| 最小相似度阈值 | 0.0(可配置) | 过滤低相关结果 |
| 大模型温度 | 0.2(可配置) | 控制回答随机性 |
| 最大生成长度 | 1200 token(可配置) | 控制响应长度 |
核心价值
- 数据隐私保护 :文档在本地处理,不传输到外部服务器
- 离线可用 :支持本地哈希向量和 echo 模式,无需网络也能运行演示
- 配置灵活 :所有关键参数可通过配置文件调整
- 易于扩展 :模块化设计,便于替换组件
现状与约束
技术栈现状
| 分类 | 技术 | 版本 | 用途 |
|---|---|---|---|
| 框架 | Streamlit | >=1.34.0 | Web 交互界面 |
| 语言 | Python | >=3.10 | 主要开发语言 |
| 文档解析 | PyPDF | >=4.0.0 | PDF 解析 |
| 表格处理 | pandas | >=2.0.0 | Excel 解析 |
| HTML解析 | beautifulsoup4 | >=4.12.0 | HTML 解 析 |
| 向量化 | sentence-transformers(可选) | >=2.7.0 | 语义向量生成 |
| 大模型 | OpenAI API | >=1.30.0 | 回答生成 |
| 向量存储 | NumPy | >=1.24.0 | 向量索引管理 |
| 配置管理 | PyYAML | >=6.0.0 | YAML 配置解析 |
约束条件
| 约束类型 | 描述 | 影响 |
|---|---|---|
| 资源约束 | 首次运行可能无网络下载模型 | 需提供降级方案(哈希向量) |
| 存储约束 | 向量文件可能较大 | 使用NumPy二级制格式压缩存储 |
| 合规约束 | 用户文档可能包含敏感信息 | 全程本地处理,不上传外部 |
| 环境约束 | 可能运行在无GPU环境 | 选用轻量级模型(bge-small) |
| 依赖约束 | 可选依赖安装可能失败 | 使用延迟加载和异常捕获 |
已有系统分析
项目采用模块化架构,各组件职责清晰:
- 数据层 : data/knowledge_base/ 存储原始文档, data/vector_store/ 存储向量索引
- 核心层 : src/rag_assistant/ 包含所有业务逻辑
- 展示层 : app.py 提供 Streamlit 交互界面
- 配置层 : config/app.yaml 集中管理所有参数
.
├── app.py # Streamlit 交互界面
├── config/
│ └── app.yaml # 应用配置文件
├── data/
│ ├── knowledge_base/ # 原始文档存储
│ └── vector_store/ # 向量索引存储
├── src/
│ └── rag_assistant/ # 核心业务逻辑
│ ├── config.py # 配置加载
│ ├── document_loader.py # 文档解析
│ ├── embedding.py # 向量化模型
│ ├── llm.py # 大模型客户端
│ ├── pipeline.py # RAG 管线编排
│ ├── schema.py # 数据模型定义
│ ├── text_splitter.py # 文本切分
│ └── vector_store.py # 向量存储与检索
├── requirements.txt # 核心依赖
├── requirements-optional.txt # 可选依赖
└── README.md # 项目说明
方案概述
核心架构
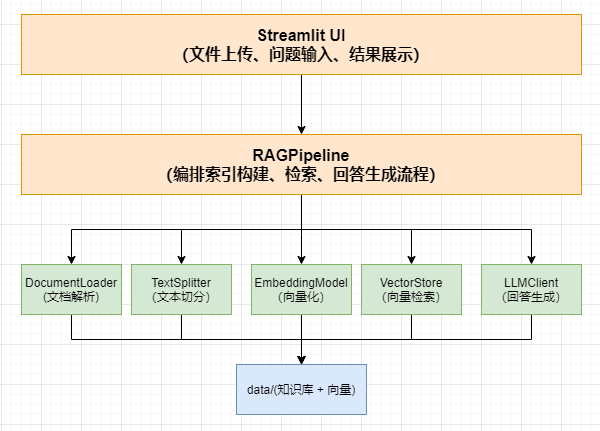
核心思路
索引构建流程
- 用户上传文档 ——> 保存到 knowledge_base 文件夹
- DocumentLoader 解析文档 ——> 生成 Document 对象列表
- TextSplitter 切分文本 ——> 生成带重叠的文本片段
- EmbeddingModel 向量化 ——> 生成向量矩阵
- VectorStore 构建索引 ——> 持久化到 vector_store 文件夹
关键设计原则
| 原则 | 实现方式 | 代码位置 |
|---|---|---|
| 模块化 | 每个组件独立封装,职责单一 | 各 .py 模块 |
| 可替换性 | 通过配置切换 Provider | embedding.py、llm.py |
| 延迟加载 | 模型按需加载,避免启动耗时 | embedding.py:_ensure_model() |
| 容错降级 | 支持本地哈希向量和 echo 模式 | embedding.py、llm.py |
| 配置集中 | 所有参数通过 YAML 管理 | config.py、schema.py |
详细设计
数据模型设计
配置类(Schema)
# 定义位置:src/rag_assistant/schema.py
@dataclass(slots=True)
class Settings:
app: AppSettings # 应用配置
documents: DocumentSettings # 文档配置
splitter: SplitterSettings # 切分配置
embedding: EmbeddingSettings # 向量化配置
retrieval: RetrievalSettings # 检索配置
llm: LLMSettings # 大模型配置
字段说明 :
| 配置类 | 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|---|
| AppSettings | title | str | 应用标题 | “本地 RAG 智能助手” |
| page_icon | str | 页面图标 | “🧠” | |
| knowledge_base_dir | Path | 知识库目录 | “data/knowledge_base” | |
| vector_store_dir | Path | 向量存储目录 | “data/vector_store” | |
| DocumentSettings | allowed_extensions | list[str] | 允许的文档扩展名 | [".pdf", “.xlsx”, “.xls”, “.txt”, “.html”, “.htm”] |
| SplitterSettings | chunk_size | int | 切分块大小 | 900 |
| chunk_overlap | int | 重叠字符数 | 120 | |
| EmbeddingSettings | provider | str | 向量化提供者 | “sentence_transformers” |
| model_name | str | 模型名称 | “BAAI/bge-small-zh-v1.5” | |
| fallback_dimension | int | 降级向量维度 | 384 | |
| RetrievalSettings | top_k | int | 检索返回数量 | 5 |
| min_score | float | 最小相似度阈值 | 0.0 | |
| LLMSettings | provider | str | 大模型提供者 | “openai_compatible” |
| model | str | 模型名称 | “gpt-4o-mini” | |
| base_url | str | API 基础地址 | “https://api.openai.com/v1" | |
| api_key_env | str | API Key 环境变量名 | “OPENAI_API_KEY” | |
| temperature | float | 温度参数 | 0.2 | |
| max_tokens | int | 最大生成长度 | 1200 | |
业务数据类
# 定义位置:src/rag_assistant/schema.
py
@dataclass(slots=True)
class Document:
text: str # 文档内容
metadata: dict[str, Any] = field (default_factory=dict) # 元信息(来源、页码等)
@dataclass(slots=True)
class SearchResult:
text: str # 检索到的文本片段
metadata: dict[str, Any] # 来源元信息
score: float # 相似度分数
@dataclass(slots=True)
class IndexBuildResult:
document_count: int # 处理的文档数
chunk_count: int # 生成的片段数
@dataclass(slots=True)
class Answer:
answer: str # 生成的回答
sources: list[SearchResult] # 引用来源列表
模块设计
DocumentLoader(文档加载器)
职责 :将不同格式的文档解析为统一的 Document 对象
支持格式 :
| 格式 | 扩展名 | 解析方式 | 特殊处理 |
|---|---|---|---|
| PyPDF 的 PdfReader | 按页拆分,记录页码 | ||
| Excel | .xlsx, .xls | pandas | 按工作表拆分,记录表名 |
| TXT | .txt | 直接读取 | UTF-8 编码 |
| HTML | .html, .htm | BeautifulSoup | 移除 script/style 标签 |
核心方法 :
def load_directory(self, directory: Path) -> list[Document]
# 输入:目录路径
# 输出:Document 列表
# 遍历目录下所有允许的文件,逐一解析
def load_file(self, path: Path) -> list[Document]
# 输入:文件路径
# 输出:Document 列表(可能多个,如多页PDF)
# 根据扩展名选择对应的解析方法
元信息生成 ( _meta 函数):
| 字段 | 说明 | 示例 |
|---|---|---|
| source | 文件完整路径 | “data/knowledge_base/doc.pdf” |
| filename | 文件名 | “doc.pdf” |
| extension | 文件扩展名 | “.pdf” |
| page | 页码(PDF专用) | 3 |
| sheet | 工作表名(Excel专用) | “Sheet1” |
代码位置 : src/rag_assistant/document_loader.py
TextSplitter(文本切分器)
职责 :按字符长度切分文本,保留重叠区域减少语义断裂
核心参数 :
| 参数 | 类型 | 说明 |
|---|---|---|
| chunk_size | int | 每个切分块的字符数 |
| chunk_overlap | int | 相邻块的重叠字符数 |
约束条件 : chunk_overlap < chunk_size (在 init 中检查)
切分算法 :
原始文本:[===============================] (长度 N)
切分结果:
块0: [===========] 位置: 0 ~ chunk_size
块1: [===========] 位置: chunk_size-overlap ~ 2*chunk_size-overlap
块2: [===========] 位置: 2*chunk_size-2*overlap ~ 3*chunk_size-2*overlap
文本归一化 ( _normalize_text 函数):
- 压缩多余空白
- 移除空行
- 每行前后去空格
代码位置 : src/rag_assistant/text_splitter.py
EmbeddingModel(向量化模型)
职责 :将文本转换为向量表示,支持真实模型和降级方案
设计模式 :延迟加载 + 降级机制
核心参数 :
| 参数 | 类型 | 说明 |
|---|---|---|
| provider | str | 向量化提供者 |
| model_name | str | 模型名称或路径 |
| fallback_dimension | int | 降级向量维度 |
属性 :
@property
def dimension(self) -> int:
self._ensure_model()
if self._model is not None:
return int(self._model.get_sentence_embedding_dimension())
return self.fallback_dimension
核心方法 :
def encode(self, texts: list[str]) -> np.ndarray:
self._ensure_model()
if not texts:
return np.empty((0, self.dimension), dtype="float32")
if self._model is not None:
vectors = self._model.encode(texts, normalize_embeddings=True)
return np.asarray(vectors, dtype="float32")
vectors = np.vstack([self._hash_embedding(text) for text in texts]).astype("float32")
norms = np.linalg.norm(vectors, axis=1, keepdims=True)
return vectors / np.clip(norms, 1e-12, None)
降级方案 ( _hash_embedding ):
当无法加载真实模型时,使用 SHA-256 哈希生成伪向量:
def _hash_embedding(self, text: str) -> np.ndarray:
"""无需下载模型的兜底方案,便于项目首次运行和离线演示。"""
vector = np.zeros(self.fallback_dimension, dtype="float32")
for token in _tokenize(text):
digest = hashlib.sha256(token.encode("utf-8")).digest()
index = int.from_bytes(digest[:4], "little") % self.fallback_dimension
sign = 1.0 if digest[4] % 2 == 0 else -1.0
vector[index] += sign
return vector
分词策略 ( _tokenize ):
- 中文:按字分词
- 英文:按词分词(字母数字序列)
- 统一转为小写
代码位置 : src/rag_assistant/embedding.py
VectorStore(向量存储)
职责 :负责向量索引的内存检索和本地持久化
存储结构 :
| 文件 | 格式 | 内容 |
|---|---|---|
| vectors.npy | NumPy 二进制 | 归一化后的向量矩阵 |
| documents.json | JSON | 文档片段及元信息列表 |
核心方法 :
| 方法 | 输入 | 输出 | 说明 |
|---|---|---|---|
build(documents, vectors) | 文档列表和向量 | 无 | 构建内存索引 |
search(query_vector, top_k, min_score) | 查询向量、返回数量、阈值 | SearchResult 列表 | 相似度检索 |
save() | 无 | 无 | 持久化到本地 |
load() | 无 | bool | 加载本地索引 |
检索算法 :使用点积计算余弦相似度(向量已归一化)
代码位置 : src/rag_assistant/vector_store.py
LLMClient(大模型客户端)
职责 :封装大模型调用,支持多种提供者和降级模式
支持的提供者 :
| Provider | 说明 | 使用场景 |
|---|---|---|
| openai_compatible | OpenAI API 兼容接口 | 生产环境 |
| local_echo | 本地模板回答 | 演示、测试 |
核心方法 :
def generate(self, question: str, contexts: list[SearchResult]) -> str
# 输入:问题、检索到的上下文片段
# 输出:生成的回答文本
Prompt 构建 :
System Prompt ( _system_prompt ):
"你是一个严谨的中文 RAG 智能助手。必须优
先依据给定的本地知识库片段回答。如果资料不
足,请明确说明不足,不要编造。回答要结构清
晰,并在适当位置提及来源。"
User Prompt ( _build_user_prompt ):
问题:{question}
本地知识库片段:
[片段 1 | 来源:xxx | 相似度:0.85]
文本内容...
[片段 2 | 来源:yyy | 相似度:0.72]
文本内容...
降级模式逻辑 :
if provider == "local_echo" 或 未配置 API Key:
return _local_answer(question,
contexts)
else:
调用 OpenAI API
代码位置 : src/rag_assistant/llm.py
RAGPipeline(RAG 管线)
职责 :编排各组件,提供统一的索引构建和问答接口
组件组合 :
self.loader = DocumentLoader(settings.documents.allowed_extensions)
self.splitter = TextSplitter(settings.splitter.chunk_size, settings.splitter.chunk_overlap)
self.embedding_model = EmbeddingModel(...)
self.vector_store = VectorStore(settings.app.vector_store_dir)
self.llm = LLMClient(settings.llm)
核心方法 :
def rebuild_index(self) -> IndexBuildResult
# 流程:加载文档 → 切分 → 向量化 → 构建索引 → 保存
# 输出:处理统计信息
def load_index(self) -> bool
# 从本地加载已构建的索引
def answer(self, question: str) -> Answer
# 流程:问题向量化 → 检索 → 生成回答
# 输出:Answer 对象(含引用来源)
代码位置 : src/rag_assistant/pipeline.py
Streamlit 应用层
职责 :提供 Web 交互界面,处理用户输入输出
页面结构 :
| 区域 | 功能 | 实现 |
|---|---|---|
| Sidebar | 知识库管理 | 文件上传、重建索引、加载索引 |
| Main | 对话界面 | 消息历史、问题输入、回答展示 |
会话状态管理 :
if "messages" not in st.session_state:
st.session_state.messages = []
# 存储对话历史
缓存策略 :
@st.cache_resource
def get_pipeline(config_path: str) -> RAGPipeline:
# 缓存管线实例,避免重复初始化
代码位置 : app.py
技术选型对比
Embedding 模型选型
| 方案 | 优点 | 缺点 | 选择 |
|---|---|---|---|
| entenceTransformers (BGE-small) | 质量高,中文支持好,轻量级 | 需要下载模型 | 推荐 |
| OpenAI Embedding API | 质量极高 | 需要联网,有成本 | 备选 |
| 本地哈希向量 | 零依赖,即时可用 | 检索质量差 | 降级方案 |
大模型选型
| 方案 | 优点 | 缺点 | 选择 |
|---|---|---|---|
| OpenAI API (gpt-4o-mini) | 质量高,响应快,成本低 | 需要联网和 API Key | 推荐 |
| 开源模型 (如 Qwen) | 本地部署,隐私保护 | 需要 GPU | 备选扩展 |
| local_echo 模式 | 零依赖,演示友好 | 无真正生成 | 降级方案 |
向量存储选型
| 方案 | 优点 | 缺点 | 选择 |
|---|---|---|---|
| NumPy + JSON | 简单轻量,无需额外依赖 | 内存检索,大数据量性能差 | 当前实现 |
| FAISS | 高效索引,支持 GPU | 需要额外安装 | 扩展方案 |
| Chroma/Pinecone | 专业向量数据库 | 部署复杂 | 扩展方案 |
文档解析选型
| 格式 | 方案 | 版本 | 理由 |
|---|---|---|---|
| PyPDF | >=4.0.0 | 轻量 | |
| Excel | pandas + openpyxl | >=2.0.0 | 支持 xlsx/xls,成熟稳定 |
| HTML | BeautifulSoup | >=4.12.0 | 简单易用,解析灵活 |
风险与应对
风险识别与缓解
| 风险编号 | 风险描述 | 严重程度 | 概率 | 缓解措施 |
|---|---|---|---|---|
| RISK-001 | Embedding 模型下载失败 | 中 | 中 | 哈希向量降级方案 |
| RISK-002 | 大模型 API Key 未配置 | 中 | 高 | local_echo 模式 |
| RISK-003 | 文档解析失败 | 低 | 中 | 异常捕获,跳过损坏文件 |
| RISK-004 | 向量文件过大导致内存不足 | 低 | 低 | 考虑引入 FAISS |
| RISK-005 | 长文档切分导致语义断裂 | 中 | 中 | 使用重叠切分 |
| RISK-006 | 配置文件缺失或格式错误 | 高 | 低 | 参数校验和默认值 |
降级机制设计
Embedding 降级流程 :
用户启动应用
│
▼
尝试加载 SentenceTransformers 模型
│
├─ 成功 → 使用真实向量
│
└─ 失败 → 使用哈希向量(提示用户质量受限)
LLM 降级流程 :
用户提问
│
▼
检查 provider 和 API Key
│
├─ provider="local_echo" → 返回检索摘要
│
├─ API Key 有效 → 调用大模型生成
│
└─ API Key 无效 → 返回检索摘要(提示未配置)
测试要点
单元测试用例
| 测试模块 | 测试场景 | 预期结果 |
|---|---|---|
| DocumentLoader | 加载正常 PDF | 返回 Document 列表 |
| 加载加密 PDF | 异常处理 | |
| 加载空文件 | 返回空列表 | |
| TextSplitter | 切分短文本 | 返回1个块 |
| 切分长文本 | 返回多个块,有重叠 | |
| chunk_overlap >= chunk_size | 抛出 ValueError | |
| EmbeddingModel | 空文本列表 | 返回空数组 |
| 模型加载失败 | 自动降级到哈希向量 | |
| VectorStore | 空索引检索 | 返回空列表 |
| 相似度过滤 | 低于阈值的结果被过滤 | |
| LLMClient | 无上下文 | 返回提示信息 |
| RAGPipeline | 无索引时回答 | 提示先构建索引 |
集成测试用例
| 测试场景 | 步骤 | 预期结果 |
|---|---|---|
| 完整索引流程 | 上传文档 → 重建索引 | 成功构建,显示文档数和块数 |
| 完整问答流程 | 提问 → 检索 → 回答 | 返回带引用来源的回答 |
| 降级模式验证 | 不安装sentence-transformers | 应用正常启动,使用哈希向量 |
| 配置热更新 | 修改配置文件 → 重启应用 | 新配置生效 |
性能测试
| 测试项 | 指标 | 目标值 |
|---|---|---|
| 文档解析速度 | 100页PDF解析时间 | < 30秒 |
| 向量生成速度 | 1000个片段向量化 | < 60秒 |
| 检索响应时间 | 单查询检索 | < 100ms |
| 问答响应时间 | 完整问答流程 | < 10秒 |
部署与运维建议
环境要求
| 分类 | 要求 | 说明 |
|---|---|---|
| Python | >= 3.10 | 推荐 3.11 |
| 内存 | >= 4GB | 模型加载和向量检索需要 |
| 存储 | >= 1GB | 知识库和向量存储 |
| 网络 | 可选 | 下载模型或调用 API 需要 |
安装步骤
# 1. 创建虚拟环境
python -m venv .venv
# 2. 激活虚拟环境(Windows)
.venv\Scripts\activate
# 3. 安装核心依赖
pip install -r requirements.txt
# 4. (可选)安装高质量向量模型
pip install -r requirements-optional.txt
# 5. 配置环境变量(如需使用大模型)
set OPENAI_API_KEY=your-api-key
# 6. 启动应用
streamlit run app.py
配置说明
配置文件位置 : config/app.yaml
关键配置项说明 :
| 配置路径 | 说明 | 建议值 |
|---|---|---|
| app.knowledge_base_dir | 知识库目录 | 相对或绝对路径 |
| splitter.chunk_size | 文本切分大小 | 500-1500 |
| embedding.model_name | Embedding 模型 | BAAI/bge-small-zh-v1.5 |
| retrieval.top_k | 检索数量 | 3-10 |
| llm.temperature | 温度参数 | 0.1-0.5 |
运维建议
日志管理 :
Streamlit 默认输出到控制台
生产环境可配置日志文件 数据备份 :
定期备份 data/knowledge_base/ 和 data/vector_store/
建议使用版本控制管理配置文件 性能优化 :
对于大规模知识库,考虑引入 FAISS 索引
定期清理过期文档并重建索引 安全建议 :
API Key 通过环境变量传递,不要硬编码
限制知识库目录的访问权限
定期更新依赖版本